The neural encoders involved in the experiments are reported below. The respective github links point to the specific commit used for generating the evaluation data.
Abstract
This paper reviews the current state and emerging trends in synthetic speech detection. It outlines the main data-driven approaches, discusses the advantages and drawbacks of focusing future research solely on neural encoding detection, and offers recommendations for promising research directions.
The observations in this paper aim to guide future state-of-the-art research in the field and to highlight the risk of overcommitting to approaches that may not stand the test of time.
This page complements the paper by providing a full evaluation of a few off-the-shelf models for synthetic speech detection, that were tested firstly on the pristine ASVSpoof 2019 LA eval dataset, and then with its variants created by neurally encoding the bona fide trials.
Bona Fide Examples
Example bona fide trials used for the performance evaluation. The encoders were configured to compress the input utterances, and the output was then decoded as WAV.
| Dataset Variant | Example ID | |||
|---|---|---|---|---|
Performance Evaluation
Summary of the balanced accuracy (BAC) and equal error rate (EER) achieved by the latest self-supervised-learning-based methods on the ASVSpoof 2019 LA eval dataset and neurally-encoded variants thereof.
The results were obtained by using the off-the-shelf weights provided by the authors of the respective detection models.
Since the detection performance is not affected by the sampling rate and the spoofed content was not modified, its decrease depends entirely on the occurrence of false alarms on bona fide trials.
Results breakdown in terms of area under the curve (AUC), equal error rate (EER), and balanced accuracy (BAC).
The sampling frequency at which each neural encoder operates was noted whenever different from 16 kHz.
| Baseline | XLSR-AASIST | XLSR-SLS | XLSR-MAMBA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | EER | BAC | AUC | EER | BAC | AUC | EER | BAC | |
| Neural Encoders | XLSR-AASIST | XLSR-SLS | XLSR-MAMBA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | EER | BAC | AUC | EER | BAC | AUC | EER | BAC | |
Since the detection performance is not affected by the sampling rate and the spoofed content was not modified, its decrease depends entirely on the occurrence of false alarms on bona fide trials.
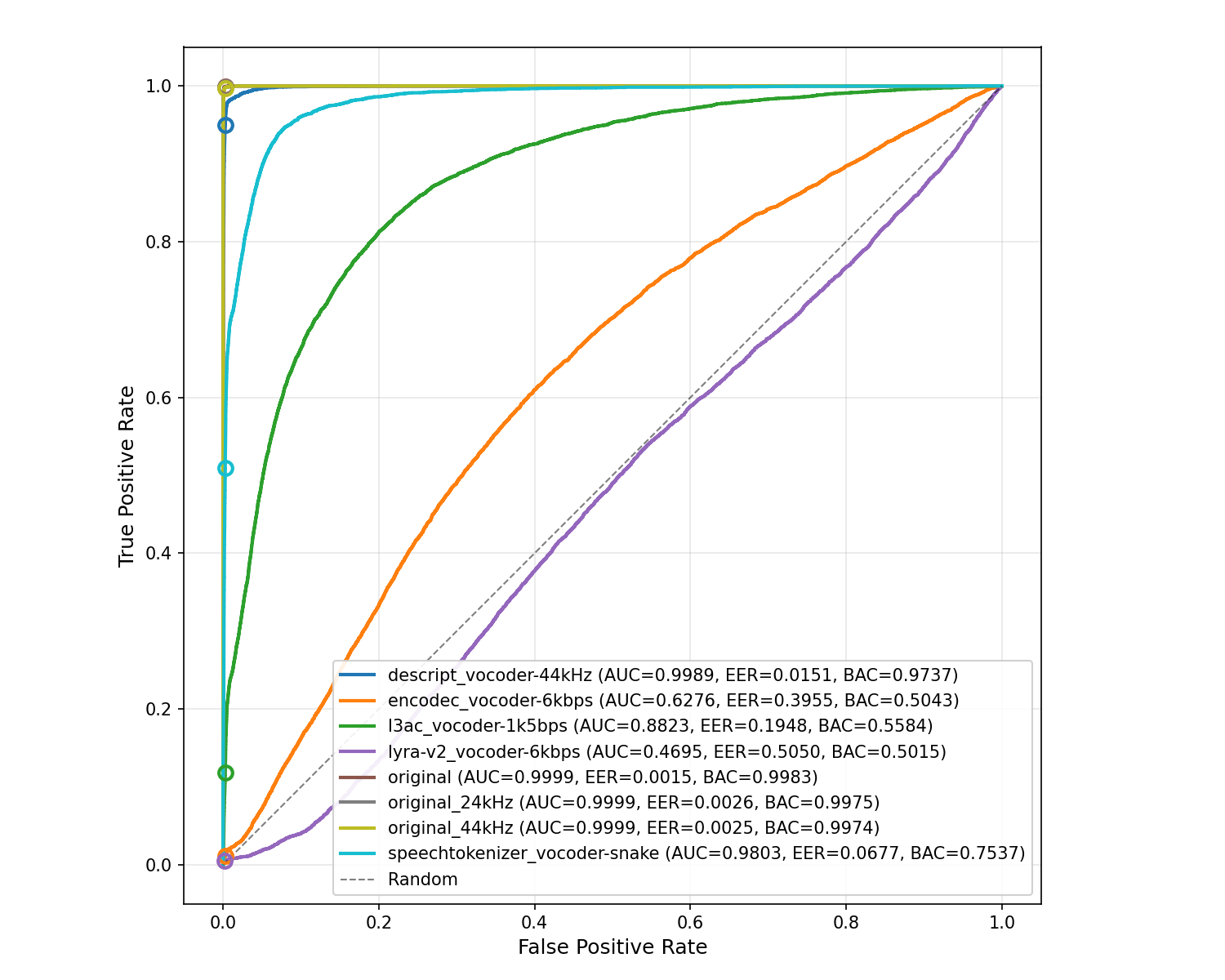
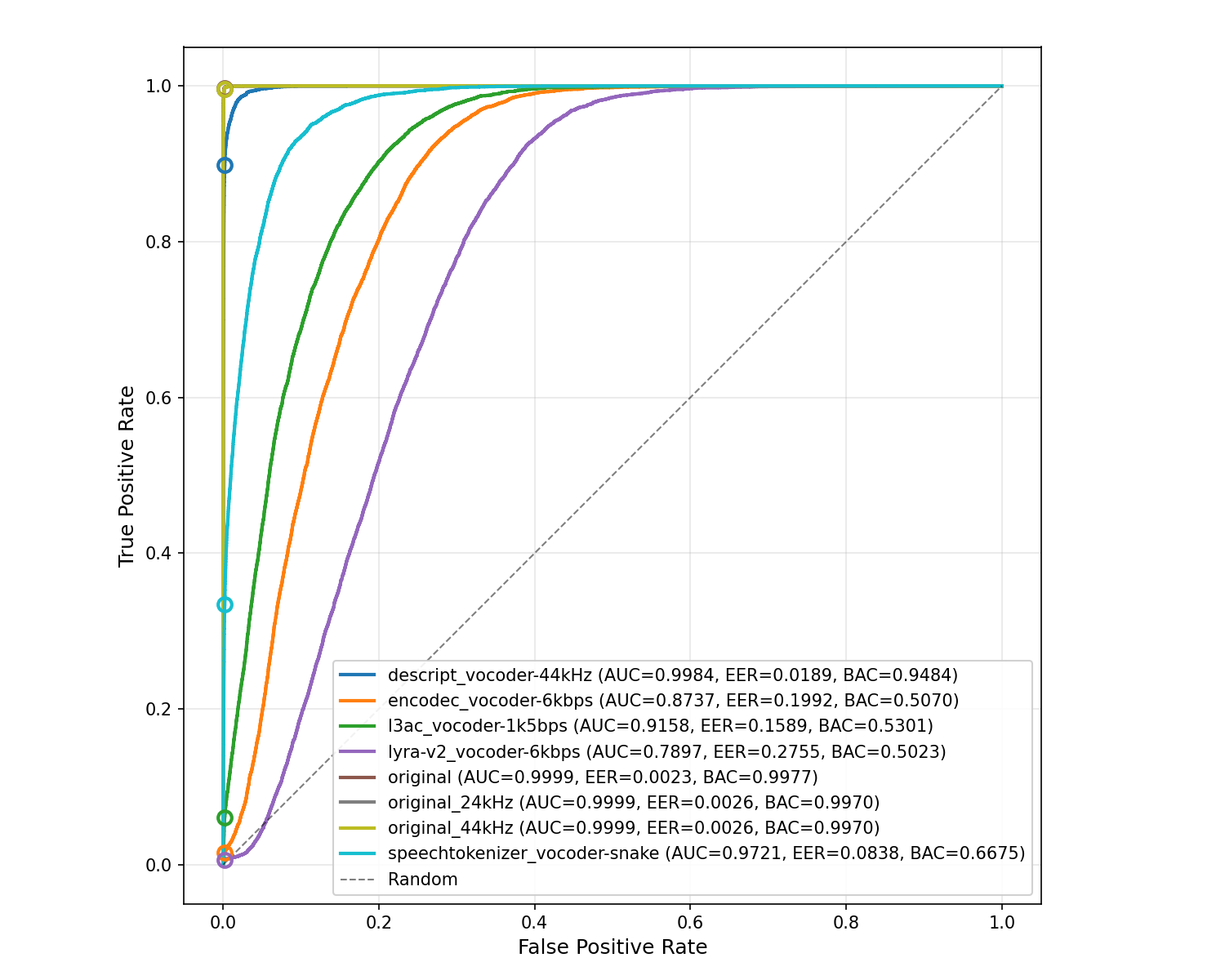
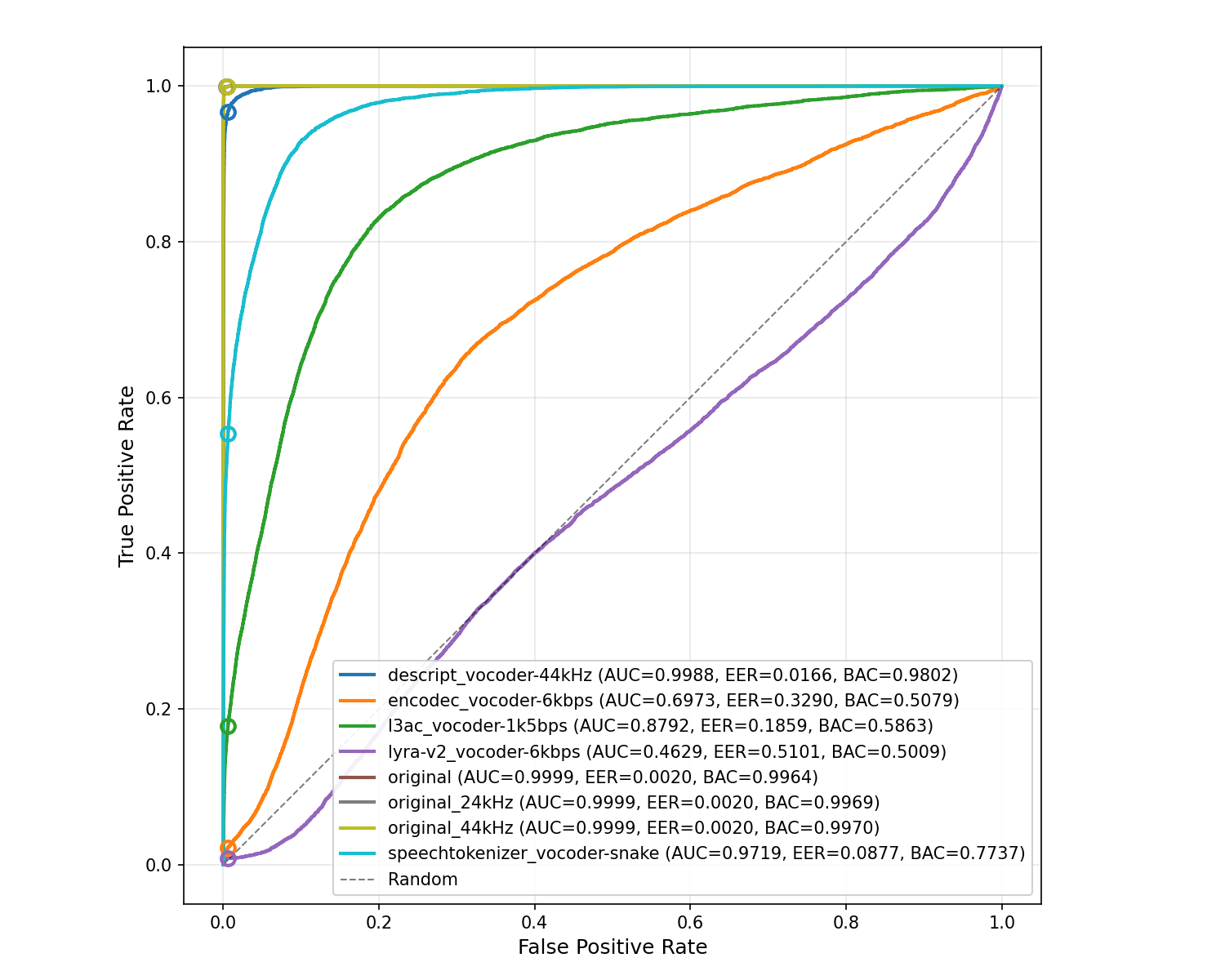
ROC curves upon ASVSpoof 2019 LA eval dataset and neurally encoded variants. The operating point for output probability of 0.5 (where, by convention, p>0.5 implies that the content is synthetic) is marked by a circle.
XLSR-AASIST
XLSR-SLS
XLSR-Mamba
Experimental Condition
BibTeX
@inproceedings{cuccovillo2026iwbf,
author = {Cuccovillo, Luca and Wang, Xin and Gerhardt, Milica and Aichroth, Patrick},
title = {Neural Encoding Detection is Not All You Need for Synthetic Speech Detection},
booktitle = {IEEE International Workshop on Biometrics and Forensics (IWBF)},
location = {Sophia Antipolis, France},
year = {2026},
pages = {1--6},
doi = {10.1109/IWBF68042.2026.11558162},
}